The current state of generative video is often characterized by a “lottery” mindset. For many creators, the process involves feeding a prompt into a model and hoping the output yields something usable. While this might suffice for social media “eye candy,” it is insufficient for creative operations leads who need to build repeatable asset pipelines. The primary friction point in this workflow is temporal drift—the tendency for an AI-generated subject or environment to morph, melt, or lose its structural integrity as soon as motion is introduced.
In a professional production context, a clip isn’t “good” just because it looks impressive in a vacuum; it’s good if it can be cut into a sequence without breaking the viewer’s immersion. Achieving this requires a transition from serendipity-based creation to controlled motion logic. This article breaks down how operators can shape camera movement and subject action while maintaining coherence by utilizing specific multi-model workflows.
The Friction of Temporal Drift in Generative Pipelines
The fundamental challenge of AI video lies in the latent space’s inability to understand physics or three-dimensional permanence. When you ask a model to “pan left while the subject walks,” the model is essentially guessing what the background and the subject should look like in the next 24 to 30 frames.
Why Usability Trumps Novelty
In a standard text-to-video workflow, the model has to generate the visual identity of the scene and the motion vectors simultaneously. This often results in a “melting” effect where a character’s face changes slightly from frame one to frame sixty, or where the background architecture shifts as the camera moves. For a creative lead, these are not just minor glitches; they are “artifact thresholds” that render the asset unusable for high-stakes projects.
Industry-wide, there is a clear trade-off: higher motion intensity usually leads to lower structural integrity. If you push for aggressive camera movement (like a fast drone shot through a forest), the model often struggles to maintain the geometric consistency of the trees. Conversely, static shots are stable but lack the cinematic energy required for modern content. The goal of a technical operator is to find the “Goldilocks zone” where motion is impactful but the pixels remain grounded.
The Image-First Mandate: Anchoring the Visual Baseline
To solve the problem of identity drift, the most effective strategy is the Image-to-Video (I2V) workflow. By generating a high-fidelity reference frame first, you provide the video model with a “single source of truth.” This is where Banana AI Image becomes the cornerstone of the pipeline.
The Single Source of Truth
Using a dedicated image generation phase allows you to lock in the lighting, texture, and character details before any motion is applied. When you start with a static image, the video model’s task is simplified: it no longer needs to “invent” a character; it only needs to animate an existing one.
Practical testing shows that using a fixed seed in the image phase—and then carrying that visual DNA into the video phase—drastically reduces the likelihood of “hallucinations.” If the initial image is 16:9 and features a specific lighting setup (e.g., golden hour rim lighting), the motion engine will prioritize maintaining those specific pixel values across the temporal sequence. Without this anchor, text-to-video models often default to generic “average” versions of the prompt, losing the specific creative direction you intended.
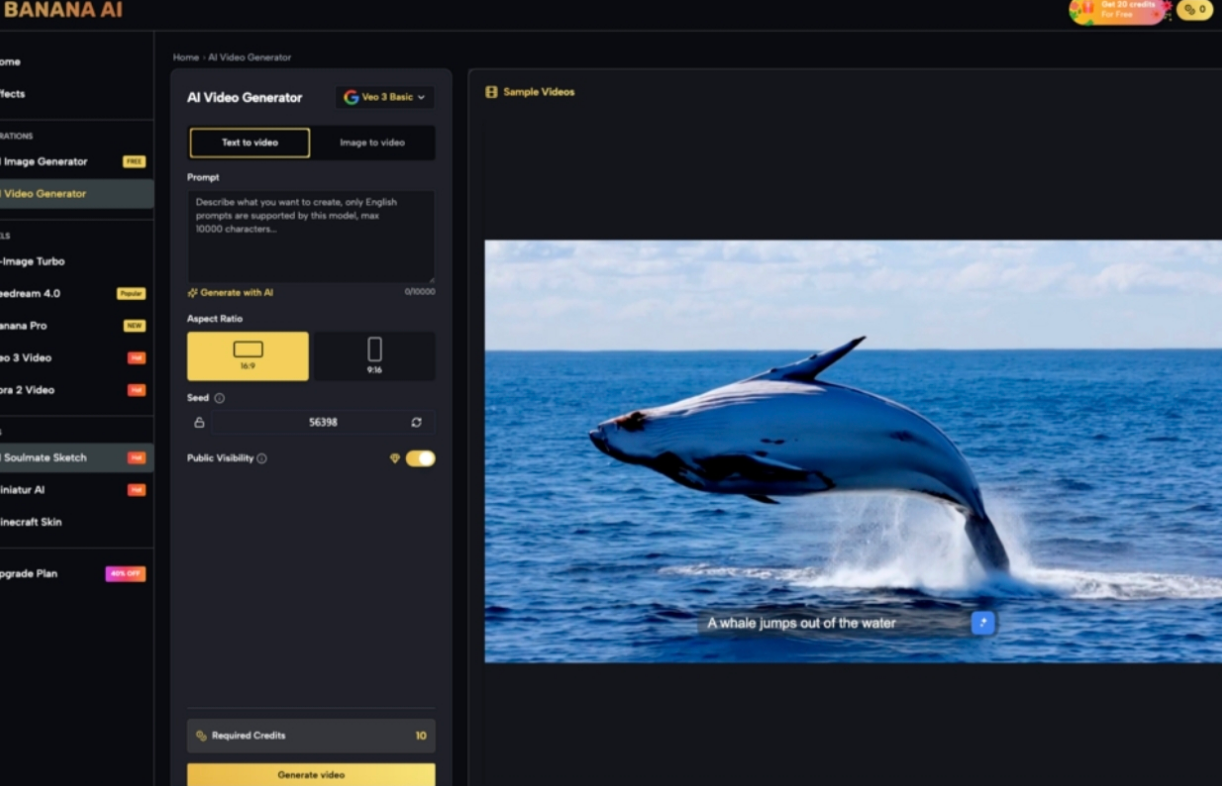
Deconstructing Motion Models: Veo 3 vs. Seedream 4.0
Not all motion engines are created equal. Within the Banana AI ecosystem, different models handle the “physics” of a scene with varying degrees of success. Choosing the right engine is less about which one is “better” and more about which one fits the specific motion profile of the shot.
Model-Specific Motion Profiles
Based on operational benchmarks, Veo 3 tends to favor fluid, naturalistic movement. It is particularly effective for “camera-only” motion where the environment needs to feel expansive and the parallax needs to be smooth. If you are simulating a slow dolly shot or a cinematic gimbal move, this model typically maintains background coherence better than more aggressive alternatives.
Seedream 4.0, on the other hand, often demonstrates a different approach to subject-specific movement. If the goal is to have a subject perform a complex action—such as pouring water or walking toward the lens—the model’s ability to retain fine detail on the moving object is critical. However, it is important to note that no model is currently perfect. There is a persistent uncertainty in how these engines interpret “velocity.” A prompt for a “fast car” might result in a car that looks like it’s going 20 mph, or it might result in the background turning into a blurred smear while the car remains static. This lack of predictable 1:1 physical realism remains a significant limitation of the technology.
Synthesizing Camera and Subject: The Prompting Hierarchy
Once the visual baseline is established through Banana AI Image, the next step is to layer motion instructions. A common mistake among operators is “motion bloat”—including too many directional cues in a single prompt. If you tell a model to “pan left, zoom in, and have the subject jump,” the latent space often gets confused, leading to visual artifacts.
Avoiding Motion Bloat
A systematic approach to prompting for motion follows a strict hierarchy:
- The Environment: Define the static elements (e.g., “interior laboratory, fluorescent lighting”).
- The Camera Path: Define the lens movement (e.g., “slow push-in, low-angle shot”).
- The Subject Action: Define the primary movement (e.g., “scientist looking through a microscope”).
By separating these components, you give the model a clearer map of what should be moving and what should remain stationary. Operators should also use keyword weight and directional cues (like “clockwise rotation” or “lateral tracking”) rather than generic terms like “cinematic movement.” Generic terms are “noisy” and often introduce random elements like lens flares or unexpected color shifts that you didn’t ask for.
Pipeline Limits and the ‘Black Box’ of Physics
As of 2026, we must maintain a degree of skepticism regarding “perfect” AI video. There are clear ceiling points where the technology currently fails. One of the primary limitations is the difficulty of maintaining 1:1 physical realism in fast-paced interaction shots. For instance, if two characters are shaking hands or a character is picking up a complex object, the geometry of the hands often merges. This “collision logic” is still a black box for generative models.
Furthermore, long-form temporal consistency remains a challenge. While Banana AI provides excellent short-form clips, trying to maintain perfect coherence over a sequence longer than 10 seconds usually requires external editing or frame-interpolation tools. Expecting a single generation to handle a complex 30-second narrative arc without any “drift” is unrealistic. A better operational strategy is to generate multiple 3-to-5-second “micro-actions” and stitch them together in post-production. This allows for tighter control over pacing and ensures that if one clip “melts,” the entire sequence isn’t ruined.
Integrating Motion Logic into Repeatable Workflows
To transition these insights into a repeatable creative pipeline, operations leads should focus on standardization. This includes establishing set aspect ratios (such as 16:9 for cinematic or 9:16 for social) and strictly managing seeds across the team. When multiple creators are working on the same project, using a shared seed from a single reference image ensures that the “visual soul” of the assets remains consistent, even if the motion prompts vary.
Auditing the Artifact Threshold
Before a clip is moved to the final edit, it should pass through an audit phase. This involves checking for:
- Geometric Stability: Do the walls or horizons shift unnaturally?
- Identity Retention: Does the subject still look like the original reference image?
- Motion Fluidity: Is the frame rate stable, or are there “stutter” frames where the model struggled to calculate the next pixel set?
By setting these clear benchmarks, teams can move away from the “trial and error” approach and toward a more industrial style of production. The future of generative media isn’t just about having the best prompt; it’s about having the most disciplined workflow. Utilizing tools like Banana AI Image for the foundation and specifically tuned motion models within Banana AI for the execution allows creators to reclaim control over the frame, turning the stochastic nature of AI into a predictable, professional asset pipeline.